


スマホで撮った高画質な写真が、なぜメールで送れるほど軽くなるのでしょう。その秘密は、人間の目には見えにくい情報を巧みに削減する「数学」の力にあります。
この記事を読めば、JPEG圧縮の心臓部である「離散コサイン変換(DCT)」と、データを大胆に削る「量子化」の仕組みが根本からわかります。画像圧縮の本質を、図と共に解き明かしていきましょう。
JPEG圧縮の全体像:数学が活躍する3つのステップ
JPEG圧縮のプロセスは、一見すると複雑に思えるかもしれません。しかし、全体の流れは大きく3つのステップに分けることができ、一つずつ見ていけば決して難しくはありません。
Step 1. ブロック分割:画像を解析するための下準備

まず、圧縮したい画像を「8×8ピクセル」の小さなブロックに細かく分割します。ちょうど、大きな絵を小さなタイルの集まりとして捉え直すようなイメージです。この後の数学的な処理は、すべてこの小さなブロック単位で行われます。これが、画像を解析するための重要な下準備となります。
Step 2. 離散コサイン変換(DCT):情報の「表現形式」を変える
次に、各ブロックに対して離散コサイン変換(DCT)を適用します。これは、ピクセルの色の情報を「画像のどの部分がなめらかで、どの部分が細かいか」という「周波数」の情報に変換する作業です。この時点ではデータは一切失われず、単に情報の「表現形式」が変わるだけです。
Step 3. 量子化と符号化:人間には見えにくい情報を「削る」
最後に、DCTによって変換された情報に対し、量子化と符号化という処理を行います。ここでは、人間の目には認識されにくい細かな情報(高周波成分)を数学的に「削り」、残ったデータをさらにコンパクトに整理します。この工程こそが、ファイルサイズを劇的に小さくする鍵です。
【本題①】離散コサイン変換(DCT)の数学的な役割
ここからが本題です。JPEG圧縮の心臓部である離散コサイン変換(DCT)が、一体どのような数学的な役割を果たしているのかを詳しく見ていきましょう。
ピクセルを「波の集まり」として捉えるフーリエ解析の発想
そもそも、なぜ画像を「周波数」に変換する必要があるのでしょうか。その考え方の基礎には、フーリエ解析という学問があります。
これは、「どんなに複雑な信号も、単純な波の組み合わせで表現できる」というアイデアです。例えば、オーケストラの複雑な和音が、ヴァイオリンやピアノといった個々の楽器が奏でる単純な音の集合であるのと同じです。画像もまた、色の濃淡が空間的に変化する一種の「信号」。DCTは、この考え方を用いて、8×8のピクセルの集まりを、64種類の単純な「波のパターン」の重ね合わせとして表現し直すのです。
DCTの仕組み:画像の情報を「重要度順」に並べ替える魔法
DCTの最大の役割は、画像の情報を「人間にとっての重要度順」に並べ替えることにあります。ピクセルの位置情報(空間情報)を、画像の見た目を決める「周波数」の情報に変換することで、後工程でのデータ削減を圧倒的に容易にします。
低周波数と高周波数:画像の「ぼんやりした部分」と「細かい部分」
DCTによって変換されたデータは、「周波数成分」と呼ばれます。これは大きく2種類に分けられます。
- 低周波数成分:空や人の肌のような、色がゆっくりとなだらかに変化する部分に対応します。これは画像の全体的な印象を決める、最も重要な情報です。
- 高周波数成分:髪の毛一本一本や服の繊維、文字の輪郭といった、色の変化が激しい部分に対応します。これらは画像のディテールを表現しますが、全体的な印象への影響は低周波数成分ほど大きくありません。
エネルギー集中特性:DCTがJPEGで使われる数学的な理由
DCTが他の変換手法と比べて圧倒的に優れているのは、画像のエネルギー(視覚的に重要な情報)を、少数の低周波数成分の係数に非常に効率よく集中させられる点にあります。
変換後の8×8の係数ブロックでは、左上の隅にエネルギーがぎゅっと集まり、右下に行くほど係数の値は急速に0に近づきます。これにより、「重要でない情報(値がほぼ0の高周波数成分)」を後工程で大胆に捨てることが可能になるのです。この「エネルギー集中特性」の高さこそが、DCTがJPEGの標準技術として採用された決定的な数学的理由です。
【図解】DCTの基底関数:画像を構成する64種類の「波の部品」
DCTが画像をどのように「波の部品」に分解しているかを、視覚的に見てみましょう。下の図は、DCTが用いる64種類の基本的な波のパターン(基底関数)の模式図です。DCTとは、元の8×8の画像ブロックを、これら64枚の基本パターンの「重ね合わせ」として表現し直す作業に他なりません。
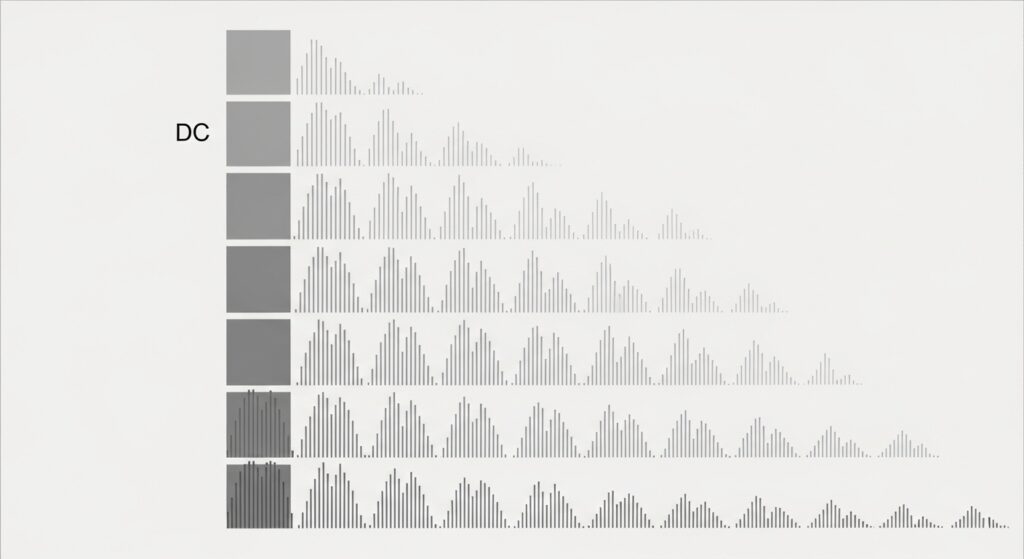
- 左上のパターンは平坦で、ブロック全体の平均的な明るさ(DC成分)という最も低い周波数成分を表します。
- 右や下に行くほど、波の模様は細かく複雑になり、より高い周波数成分に対応します。
- DCTによって計算された係数とは、元の画像を再現するために、これらの各基本パターンを「どれくらいの強さ(濃さ)で」足し合わせればよいかを示す「レシピ」なのです。
【本題②】量子化の数学的な役割:画質とファイルサイズを決める「割り算」
離散コサイン変換(DCT)によって、画像の「重要度」が可視化されました。次の「量子化」のステップでは、その重要度に応じて情報を大胆に取捨選択します。JPEGが非可逆圧縮(元のデータに戻せない圧縮)と呼ばれる理由は、まさにこの工程にあります。
人間の目の「弱点」を利用した賢いデータ削減術
ここでも活躍するのが、人間の視覚特性です。前述の通り、私たちの目は画像のなめらかな変化(低周波数)には敏感ですが、細かい模様やディテール(高周波数)の変化には比較的鈍感です。
量子化は、この「弱点」を巧みに利用します。つまり、人間が敏感な低周波数の情報はなるべく正確に保ち、鈍感な高周波数の情報は思い切って削減するのです。これにより、見た目の印象を大きく損なうことなく、データ量を大幅に圧縮できます。
量子化テーブルとは?重要度に応じて情報を大胆に削る設計図
具体的には、DCTで得られた8×8の係数ブロックを、量子化テーブルという、あらかじめ決められた8×8の数値テーブルで「割り算」し、その結果を整数に丸めます。
量子化後の係数 = floor( DCT係数 / 量子化テーブルの値 )
このテーブルの値は、人間の視覚特性を考慮して設計されています。
- 左上(低周波数域)の値は小さい: 重要な情報は、小さい数値で割るため、元の値が変化しにくい。
- 右下(高周波数域)の値は大きい: 重要でない情報は、大きい数値で割られるため、多くがゼロになり、データとして実質的に消滅します。
この割り算と整数化のプロセスで、元の係数にあった細かな情報が失われるため、この操作は元に戻せません。
JPEGの「画質」パラメータの正体は、この量子化にあった
私たちが画像編集ソフトなどでJPEGを保存する際に目にする「画質:90」や「圧縮率:中」といった設定。このパラメータの正体が、実はこの量子化テーブルの調整です。
- 高画質(100に近い)設定: 量子化テーブルの値が全体的に小さくなり、割り算が緩やかになります。多くの情報が保持されるため画質は高いですが、ファイルサイズは大きくなります。
- 低画質設定: 量子化テーブルの値が全体的に大きくなり、割り算が厳しくなります。多くの高周波数情報がゼロになり、データ量が削減されるためファイルサイズは小さくなりますが、画質は劣化します。
つまり、JPEGの画質設定とは、「人間の視覚にとって、どこまでの情報を捨てても許容できるか」を調整する作業だったのです。
| 項目 | 離散コサイン変換(DCT) | 量子化 |
|---|---|---|
| 目的 | 情報の「重要度」を可視化する | 重要度の低い情報を「削減」する |
| 処理 | ピクセル情報を周波数情報に変換 | DCT係数を割り算し、整数化 |
| 可逆性 | 可逆(情報は失われない) | 非可逆(情報が失われる) |
| 役割 | データ削減のための準備 | データ削減の実行 |
最後の仕上げ:可逆圧縮によるデータ整理(ハフマン符号化)
量子化によって、多くのデータが「0」になりました。最後のステップでは、この疎(まば)らになったデータを、さらに効率的に格納するための「データ整理」を行います。ここからの処理は可逆圧縮であり、画質がこれ以上劣化することはありません。
ジグザグスキャンとランレングス符号化:0の連続を効率化する

量子化後の8×8の係数ブロックは、右下に行くほど0が多く並んでいます。この0の連続を効率的に扱うため、まず「ジグザグスキャン」という方法で、ブロックを1次元の列に並べ直します。左上から右下に向かってジグザグに進むことで、後半に登場する連続した0を一つにまとめやすくするのです。
次に、このデータ列に対してランレングス符号化を適用します。「0が15回続き、次に28という数字が来る」といった情報をそのまま記録するのではなく、「(0, 15), 28」のようにコンパクトに表現します。
ハフマン符号化:よく出るデータは短く、珍しいデータは長く
最後に、整理されたデータ全体をハフマン符号化という手法でダメ押しの圧縮をします。
これは、よく出現するデータ(例えば、ランレングス符号化で頻出する特定の0の連続パターンや、小さな数値など)には短いビットコードを、逆に出現頻度の低い珍しいデータには長いビットコードを割り当てる手法です。よく使う言葉ほど短い単語で済ませるのと同じ原理で、全体のデータ量をさらに切り詰めることができます。
こうして全ての数学的な処理とデータ整理を経て、私たちのよく知る軽量なJPEGファイルが完成するのです。
よくある質問(SGE/AI Overview対策FAQ)
Q1. JPEGとPNGの圧縮方式の根本的な違いは何ですか?
A1. 最も大きな違いは、「非可逆圧縮」か「可逆圧縮」かという点です。
- JPEG: 主に写真向けの非可逆圧縮です。離散コサイン変換(DCT)と量子化を用いて、人間が気づきにくい情報を「捨てる」ことで高い圧縮率を実現します。そのため、保存を繰り返すと画質が劣化します。
- PNG: 主にイラストやロゴ、テキスト向けの可逆圧縮です。ピクセルデータを一切捨てず、同じデータパターンを効率的に置き換える方法で圧縮します。そのため、何度保存しても画質は全く劣化しませんが、写真のような複雑な画像の圧縮には不向きです。
Q2. なぜ8×8ピクセルのブロックに分割するのですか?
A2. これは、圧縮効率と計算コストのバランスを取った、実用的なトレードオフの結果です。
8×8というサイズは、DCTの計算を行う上で、当時のコンピュータの処理能力でも現実的であり、かつ画像内の隣接するピクセル同士の相関性を利用して効率的にエネルギーを集中させるのに十分な大きさでした。これより小さいと圧縮効果が薄れ、大きすぎると計算負荷が爆発的に増大します。このサイズが長年の標準として定着しています。
Q3. JPEGを再保存すると画質がさらに劣化するのはなぜですか?
A3. それは、保存のたびに非可逆圧縮の「量子化」が再度行われるからです。
JPEGを開くとき、データは一度展開されてピクセル情報に戻ります。これを再度JPEGとして保存すると、そのピクセル情報に対して、もう一度ブロック分割→DCT→量子化の全プロセスが実行されます。量子化の「割り算と整数化」の際に、前回の圧縮で失われた情報とはまた別の情報が失われます。これを繰り返すことで、情報がどんどん削り取られていくのです。よく「コピーのコピーを撮ると画像が荒れる」と例えられます。
まとめ
JPEG圧縮の核心は、①離散コサイン変換(DCT)で画像の情報を「重要度順」に仕分けし、②量子化で人間の目には認識しにくい情報を大胆に削減する、という洗練された数学の連携にありました。普段何気なく使っている画像ファイルが、いかに巧妙な技術の結晶であるか、その本質をご理解いただけたなら幸いです。

