


「OK Google、明日の天気は?」
「Hey Siri、3分のタイマーをセットして」
今や私たちの生活にすっかり溶け込んでいる、スマートフォンの音声アシスタント。
とても便利ですが、ふと「どうして私たちの言葉を正確に理解できるんだろう?」と不思議に思ったことはありませんか?
その技術の裏側には、実は「マルコフモデル」という、「確率」という数学の道具を使って未来を予測する、賢い考え方が隠されています。
この記事では、音声認識を支えるこの「マルコフモデル」の秘密を、専門用語や数式は一切使わずに解き明かしていきます。
少し難しそうに聞こえるかもしれませんが、ご安心ください。
「天気予報」という身近な例え話を使えば、誰でもその仕組みを驚くほど直感的に理解できるはずです。
そもそも「マルコフモデル」って何?~未来を予測するシンプルな考え方~
音声認識の秘密と聞いて「マルコフモデル」という言葉が飛び出すと、なんだか難しそうに感じますよね。
でも、全く心配いりません。ここでの「モデル」とは、「考え方」や「物事をシンプルに捉えるためのルール」くらいの意味です。
そしてマルコフモデルは、驚くほど単純な数学的ルールに基づいています。
その感覚を掴むために、身近な天気予報を例に見ていきましょう。
今日の天気は、昨日の天気で決まる?
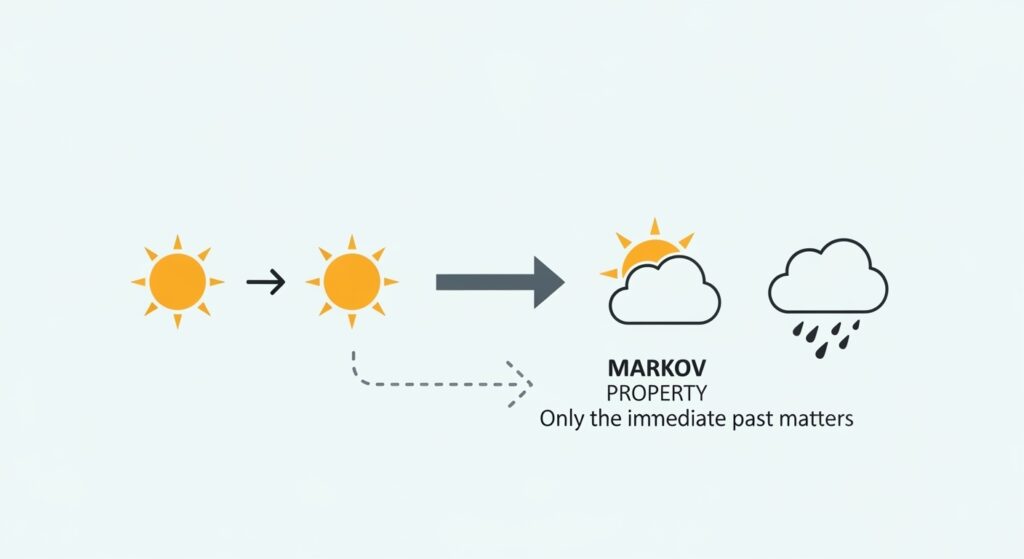
もしあなたが天気予報士だとして、「明日の天気」を予測するとします。
手元には「過去1年間の天気の記録」と「今日の天気」の情報があります。どちらを一番重視するでしょうか?
おそらく、多くの方が「今日の天気」と答えるはずです。
もちろん過去のデータも大事ですが、一番影響が大きそうなのは直前の状態ですよね。
マルコフモデルは、この考え方をさらに一歩進めて、「未来を予測するのに必要なのは、現在の情報だけ」と割り切ってしまう考え方です。
例えば、以下のような非常にシンプルなルールだけを考えます。
- もし今日が「晴れ」なら、明日は80%の確率で「晴れ」、20%の確率で「雨」。
- もし今日が「雨」なら、明日は60%の確率で「雨」、40%の確率で「晴れ」。
このように、1週間前や1ヶ月前の天気がどうだったかは一切無視して、「今」の状態から「次」の状態が確率的に決まる。
これがマルコフモデルの基本的なアイデアです。
マルコフモデルの核心:「未来は『今』だけで決まる」という潔さ
「過去を全部無視しちゃって大丈夫なの?」と不安になるかもしれません。
しかし、この「未来は、現在の状態にのみ依存し、過去の状態には依存しない」という潔さこそが、マルコフモデルの最大の強みなのです。
この性質を、少し専門的な言葉でマルコフ性と呼びます。
なぜこの性質が重要なのでしょうか。
もし1年前からの天気をすべて考慮して未来を予測しようとすると、計算はとてつもなく複雑になります。
ですが、「今日の天気だけで明日を決める」というルールなら、考えることが一気に減り、非常にシンプルになりますよね。
この「問題を単純化してくれる」という強力なメリットがあったからこそ、マルコフモデルは一見すると捉えどころのない音声という現象を、コンピューターが計算できる数学の問題に落とし込む上で、かつて大活躍することになったのです。
音声認識とマルコフモデルは、どう繋がるの?
マルコフモデルのシンプルなルールが分かったところで、次なる疑問は「それがどうやってSiriのような音声認識と関係するの?」ということですよね。
ここからは、いよいよ両者を繋ぎ合わせていきます。
音声認識のゴールは「最も“それらしい”言葉を探すこと」
まず、音声認識の大事なポイントを一つ。
コンピューターは、私たちの話した声を「100%完璧な正解」として聞き取っているわけではありません。
私たちの声には、その日の体調、周りの雑音、人それぞれの話し方のクセなど、たくさんの「曖昧さ」が含まれています。
そのため、音声認識のゴールは「完璧な正解」を探すのではなく、聞こえてきた音声データに対して「確率的に、最も“それらしい”言葉の候補は何か」を探し出すことなのです。
この「確率的に最も“それらしい”ものを探す」という考え方が、マルコフモデルの得意分野とぴったり一致します。
ここで登場!「隠れマルコフモデル(HMM)」という強力な助っ人

音声認識で実際に使われるのは、マルコフモデルを少しだけパワーアップさせた隠れマルコフモデル(HMM)です。
「隠れ」という言葉が、最大のキーワードになります。
また、天気予報の例え話で考えてみましょう。
あなたは窓のない部屋にいる友人と電話しています。あなたには、友人が今日何をしたか(「散歩した」「買い物に行った」など)は聞こえますが、外の天気は分かりません。
この関係性を表にすると、以下のようになります。
| 天気予報の例え | 音声認識の場合 | |
|---|---|---|
| 観測できること(表層) | 友人の行動報告(「散歩した」) | マイクが拾った音声データ |
| 隠れていること(深層) | 本当の天気(「晴れ」) | 話者が意図した言葉・音素 |
友人の「散歩した」という報告から、「たぶん外は晴れているんだろうな」と隠れた状態を推測しますよね。
これが隠れマルコフモデルの基本的な考え方です。
これを音声認識に当てはめると、私たちは、観測できる「音声データ」から、その背後にある「隠れた言葉」を推測している、ということになります。
人間の声を「音のパーツ」に分解する
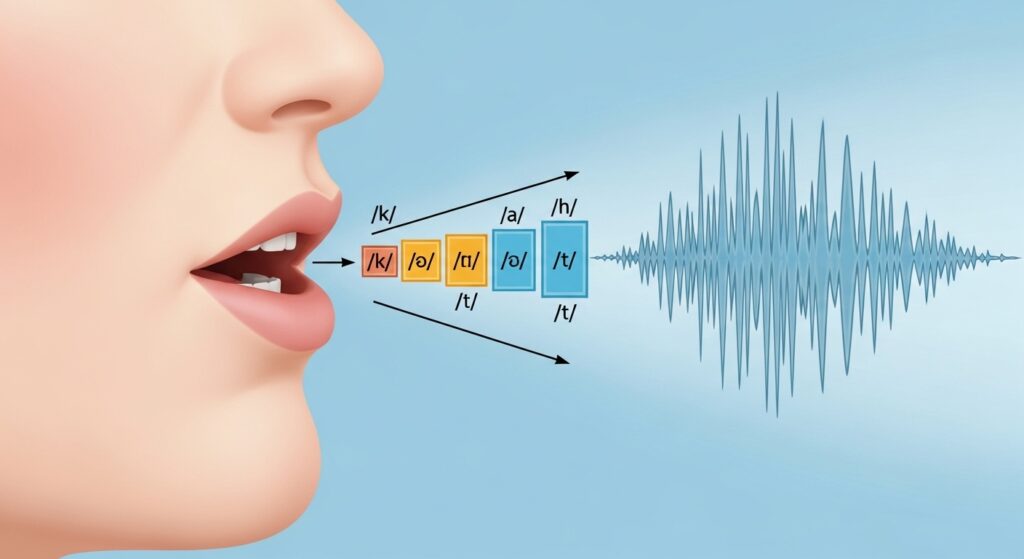
コンピューターは、「こんにちは」という言葉を一つの塊として認識しているわけではありません。
実は、私たちの言葉を音素(おんそ)と呼ばれる、非常に小さな「音のパーツ」に分解して処理しています。
例えば、「cat」という単語なら「/k/」「/æ/」「/t/」という3つの音のパーツの連なりとして捉えるイメージです。
隠れマルコフモデル(HMM)がやっているのは、マイクから入力された音声データをもとに、「最も“それらしい”音のパーツの並び順」を推測すること。
そして、そのパーツの並び順を辞書と照らし合わせて、最終的に「cat」という単語に変換しているのです。
【数式不要】隠れマルコフモデル(HMM)の3つの秘密のルール
コンピューターは、まるで優秀な探偵のように、3つの確率的な手がかり(ルール)を元に、聞こえてきた音声の正体を突き止めます。
これから紹介するルールは、実際には確率分布という数学の言葉で表現されますが、ここではその心だけを抜き出して見ていきましょう。
ルール①:最初の音は何になりやすい?(最初の文字の確率)
まず、HMMは「会話が、どの“音のパーツ”から始まることが多いか」をあらかじめ知っています。
例えば、日本語の会話でいきなり「ん」の音から始まる単語はほとんどありませんよね。
一方で、「こ」や「わ」のような音から始まる単語はたくさんあります。
このように、HMMは「この音は文の最初にきやすい」「この音はきにくい」という出現率をデータとして持っています。
これにより、推測を始めるための、的外れではないスタート地点を決めることができます。
ルール②:この音の次には、どの音が来やすい?(文字の繋がりやすさの確率)
次にHMMが使うのが、「ある“音のパーツ”の次に、どの“音のパーツ”が繋がりやすいか」という知識です。
これは、私たちが無意識に知っている言語のルールそのものです。
例えば、「し」という音が聞こえたら、その次に来る音は何でしょう?
「か」(しか)、「ん」(しん)、「て」(して)など、ある程度候補は絞られますが、いきなり「づ」が来ることはまず考えにくいですよね。
HMMは、膨大な言語データから「この音の次にはこの音が来る確率が高い」という繋がりやすさを学習しています。
このルールのおかげで、無数にある音のパーツの組み合わせから、ありえない並び順を排除し、言語として自然な候補だけを効率的に探し出すことができるのです。
ルール③:その音は、どんな風に聞こえる?(声の特徴の確率)
最後のルールが、HMMが「隠れ」モデルと呼ばれる理由と深く関わっています。
これは「ある“音のパーツ”(隠れた正解)が、実際にどんな“音声データ”(観測できるもの)として聞こえるか」という確率です。
例えば、私たちが「あ」と発音したとします。
その「あ」は、声の高い人、低い人、早口な人、ゆっくりな人、風邪気味の人など、状況によって聞こえ方が全く異なります。
このルールは、その逆を考えます。
「もし正解が“あ”だとしたら、マイクが拾ったこの音声データが観測される確率はどれくらいか?」を計算するのです。
これにより、様々な話し方やノイズといった「曖昧さ」や「揺らぎ」に対応し、「この音声は、たぶん“あ”を発音したものだろう」と柔軟に判断できます。
3つのルールが連携して答えを導く
これら3つのルールを巧みに組み合わせることで、HMMは聞こえてきた音声に対して、最も確率の高い単語の並び順を、最終的な答えとして導き出しているのです。
マルコフモデルの限界と、現代のAI技術
ここまで隠れマルコフモデル(HMM)の賢い仕組みを見てきましたが、「じゃあ、今のSiriやGoogleアシスタントも、全く同じ仕組みで動いているの?」と聞かれると、答えは「No」です。
HMMは音声認識の歴史に大きな一歩を刻んだ画期的な技術でしたが、いくつかの弱点もありました。
そして現在、その弱点を克服した、さらに賢いAI技術が主役となっています。
「今」しか見ないことの弱点
マルコフモデルの最大の強みは、「未来は『今』だけで決まる」というシンプルさでした。
しかし、これは同時に最大の弱点でもあります。なぜなら、私たちの話す言葉は、もっと長い文脈に影響されるからです。
例えば、次の二つの文章を考えてみてください。
- 川の土手に座って、魚釣りをした。
- 銀行の窓口で、お金をおろした。
私たち人間は、文全体の意味から「どて」と「まどぐち」を区別できます。
しかし、「今」の直前の音しか見ることができないHMMは、こうした長い文脈を理解するのが非常に苦手です。
そのため、同音異義語の判別などで間違いを起こすことがありました。
もっと賢い「ディープラーニング」の登場 🤖
この「文脈がわからない」という弱点を克服したのが、現代のAI技術の主役であるディープラーニングです。
ディープラーニングは、HMMよりもはるかに広い範囲の、つまり文章全体のデータから特徴を学習することができます。
まるで文の初めから終わりまでを一度に見渡して、「あ、この文脈ならこちらの単語の方が自然だ」と判断できるようなものです。
この能力のおかげで、音声認識の精度は飛躍的に向上しました。
現在の音声アシスタントが、非常に複雑な言い回しや長い文章でも高い精度で聞き取れるのは、このディープラーニング技術の恩恵が大きいのです。
それでもマルコフモデルを学ぶ意味
「じゃあ、HMMを学んでも意味がなかったの?」と思うかもしれませんが、そんなことは全くありません。
HMMが確立した「曖昧な現実の問題を、確率という数学的な道具を使って解決する」という考え方は、現代のAI技術にも通じる、非常に重要な基礎となっています。
HMMを学ぶことは、自動車の仕組みを理解するために、エンジンの基本的な原型を学ぶようなもの。
それは、より複雑な最新技術を理解するための、揺るぎない土台となってくれます。
今回学んだ知識は、あなたがこれからAIのニュースに触れるとき、きっと深い理解を与えてくれるはずです。
音声認識とマルコフモデルに関するQ&A
Q1. マルコフモデルはもう音声認識で使われていないの?
A. 主流ではありませんが、今でも活躍しています。
現在のSiriやGoogleアシスタントのような大規模なシステムでは、ディープラーニングが主役です。
しかし、HMMが完全に使われなくなったわけではありません。
特定の条件下では、ディープラーニングとHMMを組み合わせたハイブリッド方式が使われることがあります。
また、学習データが少ない場合や、特定の機器に組み込むような小規模な認識システムでは、HMMのシンプルさが利点となり、今でも有効な選択肢として活用されています。
Q2. HMMは音声認識以外にも応用できるの?
A. はい、様々な分野で応用されています。
HMMの「観測できるデータから、隠れた状態を推測する」という考え方は非常に汎用性が高く、多くの分野で使われています。
例えば、以下のような応用例があります。
- 生物学🧬: DNAの塩基配列(観測データ)から、遺伝子の領域(隠れた状態)を発見する。
- 金融📈: 株価の変動(観測データ)から、現在の市場が上昇トレンドか下降トレンドか(隠れた状態)を推定する。
- 自然言語処理: 文章中の単語(観測データ)が、名詞・動詞・形容詞のどれなのか(隠れた状態=品詞)を推定する。
Q3. 自分でマルコフモデルを試すことはできますか?
A. プログラミングの知識があれば可能です。
もしあなたがプログラミングに興味があれば、自分で簡単なマルコフモデルやHMMを動かしてみることができます。
特にPythonというプログラミング言語には、「hmmlearn」のような、HMMを簡単に扱えるライブラリ(便利な道具セット)が用意されています。
これらを使えば、複雑な数式を自分で組むことなく、HMMがどのように動くのかを実際に試して、より深い理解を得ることができるでしょう。
まとめ:音声認識の「はじめの一歩」を理解したあなたへ
この記事では、Siriなど音声認識の裏側を支えた「マルコフモデル」の基本的な仕組みを解説しました。
「未来は『今』だけで決まる」というシンプルな数学的考え方が、声という曖昧な情報から言葉を推測する「隠れマルコフモデル」へ応用されたこと、ご理解いただけたでしょうか。
このAIの考え方に興味が湧いた方のために、今後当サイトでは「ディープラーニング」のような、より現代的な技術についても解説していく予定です。
音声認識の、さらに奥深い世界へご案内しますので、ぜひ楽しみにお待ちください。

